Dozent: Prof. Dr. Stefan Noll
ÜBERBLICK
- Einführung in das Thema: Datenbanken, Informationen und Objekte
- Informationssysteme
- Datenbanken
- SQL
- Datenbankentwurf
- E-R-Modell
- Normalformen
- Übungen aus dem Seminar
Datenbanken
—> eine Datenbank ist zuständig für
- Aufbewahrung von Daten
- langfristig
- sicher
- für verschiedne Verwendungen
Datenbanken und Informationssysteme
- Was sind und was machen Informationssysteme?
—> Informationen verwalten - Google?
—> Suchmaschine —> ist ein Informationssystem, nutzt Datenbanken, ist aber keine Datenbank - Was unterscheidet eine Datenbank?
—> sind komplexe Abfragemöglichkeiten
—> Speicherung von Daten
Daten, Informationen und Objekte
- Was sind eigentlich Informationen, was sind Daten?
—> Daten sind meist ohne Kontext —> einfach
—> Informationen sind Daten mit Bedeutung im Kontext - Objekte der realen Welt in Datenbanken?
—> Eine Datenbank kann praktisch alle Arten von Daten und Informationen speichern
—> muss aber reduziertes Modell bilden und dann die modellierten Daten (=Datenobjekte) im
Rechner und in den Datenbanken speichern
INFORMATIONSSYTEME
Was ist ein Informationssystem?
—> ein System, das Informationen verwaltet
Information:
- Daten <—> Informationen <—> Wissen:
- Daten —> „nackte“ Bits
- Informationen —> Daten in einem Kontext, der deren Interpretation erlaubt
- Wissen —> Gewinnung von „neuen“ Informationen/Wissen aus Vorhandenem - fließende Grenzen
- Sichtweise hängt von der gewählten Abstraktionsebene ab —> aus manchen Perspektiven erscheinen die Daten als „nackt“; aus anderen schon als Kontextinformationen
- Abstraktionsebene muss klar gewählt werden —> Objekte müssen klar gewählt werden
—> dies ist der Gegenstand div. Ansätze zur Informations-Modellierung
—> Unterschied zu Daten? —> keine einfache Antwort
—> im Zusammenhang mit Datenbanken und Informationssystemen
- nur informelles/intuitives Verständnis der Begriffe
- Präzisierung höchstens im speziellen Kontext (Datenmodell, Anwendung)
- nur informelles/intuitives Verständnis der Begriffe
- Präzisierung höchstens im speziellen Kontext (Datenmodell, Anwendung)
—> was heißt intuitiv?
- Information ist der Oberbegriff von Daten
- Daten sind Spezielle, einfache Informationen
- Daten werden oft als atomar (=unzerlegbar) angesehen
—> es gibt aber auch komplexe (=zerlegbare) Daten wie zum Beispiel Objekte - es gibt auch Informationen, die keine Daten sind, wie beispielsweise Gesetzmäßigkeiten, Zusammenhänge, Kommentare
—> mathematisch-philosophische Überlegung zum Informationsbegriff: Informationstheorie
Verwalten:
- Bereitstellen von Operationen auf den „Informations“-Objekten
- speichern
- wiederauffinden
- hinzufügen
- verändern
- löschen
- „geeignet kombinieren“ - die Wahl der Operationen hängt mit der gewählten Abstraktionsebene ab —> Operationen müssen zu den repräsentierten Objekten passen
- ein Operatives Modell für Daten / Informationen / Wissen muss also neben geeigneten Abstraktionsmittel für Objekte auch solche für Operationen umfassen
—> ein Informationssystem ist also eine Implementierung eines Modells für Daten / Informationen / Wissen auf eine bestimmten Abstraktionsebene
—> ist also nicht (beinahe) jede Anwendung ein Informationssystem?
ja, aber:
- „jede Anwendung“ ist typischerweise sehr speziell auf die Bedürfnisse eben dieser Anwendung ausgerichtet
- generische Informationssysteme
—> bilden die Grundlage für viele konkrete Anwendungssysteme
—> haben Gemeinsamkeiten in den Anforderungen an die Informationsmodellierung (Objekte
und Operationen)
—> also eine Plattform für die effiziente und effektive Realisierung von „Daten-/ Informations-/
Wissens-lastigen" Anwendungen bieten - die Überlegungen zeigen, dass
1. Informationssysteme (fast) überall benötigt werden
2. eine Vielzahl von unterschiedlich ausgerichteten Informationssystemen gibt —> je nach Abstraktionsebene und/oder Anwendungsklasse
Definition Informationssystem:
- ein System, das große, gemeinsam benutzte Daten-/Informations-/Wissensmenge „verwaltet“
- für eine ganze Reihe von Anwendungsprogrammen —> generischer Aspekt
- und zwar
- sicher, zuverlässig und verlässlich
- effizient und effektiv
- mit verschiedenen benutzerfreundlichen Schnittstellen —> für Benutzer mit unterschiedlichen Anforderungen, Kenntnissen und Bedürfnissen
Einige relevante Aspekte:
Modellierung
|
Wie werden Daten/Informationen im System beschrieben?
|
Manipulation
|
Wie greift man auf Daten (lesend und ändernd) zu? —> Quer Languages
|
Fehlertoleranz
|
Garantien im Fall von Crashs
—> transaktionsorientierte Verarbeitung |
Effizienz
|
Performance
—> Indexstrukturen
|
Was sind Datenbanken?
—> die Aufgabe von Datenbanken
- ist es Daten langfristig aufzubewahren
- Daten vor Verlusten zu sichern
- Dienstleistungen für mehrere Kunden
—> Anwendungsbeispiel Musikversand
Daten in Tabellenform (SQL)
- Albumtabelle speichert relevante Informationen zu CD-Alben
—> jedes Album wird über eine Albumnummer (=Primary Key) identifiziert - Musikertabelle enthält Informationen zu den Künstlern
—> Musikernummer (=Primary Key) - Tracktabelle mit Liedern, Position auf dem Album und Laufzeit
—> Albumnummer wird verwendet

—> Was passiert ohne Datenbanken? —>Datenredundanz
- Basis- oder Anwendungssoftware verwaltet ihre eigenen Daten in ihren eigenen (Datei-)Formaten, z.B in Unternehmen:
- Textverarbeitung: Texte, Artikel und Adressen
- Buchhaltung: Artikel, Adressen
- Lagerverwaltung: Artikel, Aufträge
- Auftragsverwaltung: Aufträge, Artikel, Adressen
- CAD-System: Artikel, Technische Bausteine - Daten sind redundant: mehrfach gespeichert; Probleme:
—> Verschwendung von Speicherplatz
—> „Vergessen“ von Änderungen
—> keine zentrale, genormte Datenhaltung - andere Software-Systeme können große Mengen von Daten nicht effizient verarbeiten
- mehrere Benutzer oder Anwendungen können nicht parallel auf den gleichen Daten arbeiten, ohne sich zu stören
- Anwendungsprogrammierer/Benutzer können Anwendungen nicht programmieren/benutzen ohne
- interne Darstellung der Daten
- Speichermedien oder Rechner
zu kennen (Datenunabhängigkeit nicht gewährleistet) - Datenschutz und Datensicherheit sind nicht gewährleistet
—> Mit Datenbanken —> Datenintegration
- Die gesamte Basis- und Anwendungssoftware arbeitet auf denselben Daten, z.B. Adressen und Artikel werden nur einmal gespeichert
- Datenbanksysteme können große Datenmengen effizient verwalten (Anfragesprachen,
Optimierung, Interne Ebene)
- Benutzer können parallel auf Datenbanken arbeiten (Transaktionskonzept)
- Datenunabhängigkeit durch 3-Ebenen-Konzept
- Datenschutz (kein unbefugter Zugriff) und Datensicherheit (kein ungewollter Datenverlust)
werden vom System gewährleistet
Prinzipien
- DBMS: DatenBankManagmentSystem
- DBS: DatenBankSystem = DBMS+Datenbank
Kürzel
|
Begriff
|
Erläuterung
|
DB
|
Datenbank
|
Strukturierter, von DBMS verwalteter Datenbestand
|
DBMS
|
Datenbankmanagement-
system |
Software zur Verwaltung von Datenbanken
|
DBS
|
Datenbanksystem
|
DBMS plus Datenbank(en)
|

Merkformel:

Grundmerkmale von DBMS
- verwalten persistente (langfristig zu haltende) Daten
- verwalten große Datenmengen effizient
- Datenbankmodell, in dessen Konzepten alle Daten einheitlich beschrieben werden (Integration)
- Operationen und Sprachen sind deskriptiv, getrennt von einer Programmiersprache
- Transaktionskonzept, Concurrency Control: logisch zusammenhängende Operationen atomar (unteilbar), Auswirkungen langlebig, können parallel durchgeführt werden
- Datenschutz, Datenintegrität (Konsistenz), Datensicherheit

DBS
—> es wird unterschieden zwischen generischen und spezifischen Datenbanksystemen
generische DBS
|
spezifische DBS
|
für beliebige Anwendungen gedacht
|
nur für spezielle Anwendungsfelder geeignet (z.B. Multimedia-DB, Bild-DB, Geo-IS)
|
—> generische DBS werden meist nach dem unterstützten Datenmodell klassifiziert:
- relationale Datenbanken
- objekt-orientierte Datenbanken
- hierarchische Datenbanken
- Entity-Relationship Datenbanken
—> Ein Datenmodell ist eine Zusammenstellung von bestimmten Konzepten zum Modellreihen von Daten in der realen Welt und/oder im Rechner (z.B. Tabellen im relationalen Modell, Klassen OO-Modellen)
—> die alternative Bezeichnung „Datenbankmodell“ wird selten gebraucht und suggeriert eher die Modellierung der Datenstrukturen im Rechner als die von Konzepten in der realen Welt
Datenhaltung
Die einfachste Form der "Datenhaltung" ist das Ablegen von Daten in einer Textdatei, wie zum Beispiel in einem Editor
—> dabei spielt die Struktur keinerlei Rolle, da es keine Überschriften, Spalten oder Zeilen in einem Editor gibt
—> „Suche“ geschieht in Textdateien ausschließlich mittels „pattern matching“ durch den jeweiligen Editor:
—> inhaltlich motivierte Fragen lassen sich nicht dadurch beantworten
—> Änderungen in solchen „Datei-Datenbanken“ lassen sich auch durch Zeichenersetzung mittels des Texteditors durchführen
—> dabei können „sinnvolle“ Änderungen entstehen (wie etwa ein Trainerwechsel)
—> aber man kann auch z.B. einfach nur alle Vorkommen von „a“ durch „@“ ersetzen
In einer „echter“ Datenbank dagegen, werden Daten „bewusst“ in strukturierter Form gehalten
—> man kann Zeilen, Spalten und Felder voneinander unterscheiden und haben eine eigenständige Bedeutung
—> Spalten- und Tabellenbezeichner sind von Feldeinträgen unterschieden und haben eine eigenständige Bedeutung
—> dabei sind Datenbanken eigentlich auch nur spezielle Dateien, die aber von einem sehr speziellen „Editor“ verwaltet werden: dem DBMS
Wesentlicher Unterschied zwischen Datenbanken (mit DMBS) und Dateien (mit Editoren) ist aber die Möglichkeit, gezielte inhaltlich motivierte Anfragen zu stellen, die automatisch vom DBMS durch Bilden von Antworttabellen beantwortet werden
Prinzipien
- Grundprinzip moderner Datenbanksysteme
- 3-Ebenen-Architektur (physische Datenunabhängigkeit, logische Datenunabhängigkeit)
- Trennung zwischen Schema (etwa Tabellenstruktur) und Instanz (etwa Tabelleninhalt) - angelehnt an 9 Codd’sche Regeln..
..diese lauten:
Integration
|
einheitliche, nichtredundante Datenverwaltung
|
Operationen
|
Speichern, Suchen, Ändern
|
Katalog
|
Zugriffe auf Datenbankbeschreibungen im Data Dictionary
|
Benutzersichten
|
für unterschiedliche Anwendungen brauchen wir eine unterschiedliche Sicht auf den Datenbestand
|
Integritätssicherung
|
Korrektheit des Datenbankinhalts
|
Datenschutz
|
Ausschluss unauthorisierter Zugriffe
|
Transaktionen
|
mehrere DB-Operationen als Funktionseinheit
|
Synchronisation
|
parallele Transaktionen koordinieren
|
Datensicherung
|
Wiederherstellung von Daten nach Sytsemfehlern
|
System-Architekturen
- Beschreibung der Komponenten eines Datenbanksystems
- Standardisierung der Schnittstellen zwischen Komponenten
- Architekturvorschläge
- ANSI-SPARC-Architektur —> Drei-Ebenen-Architektur
- Fünf-Schichten-Architektur —> beschreibt Transformationskomponenten im Detail
Klassifizierung der Komponenten
Definitionskomponenten
|
Datendefinition, Dateiorganisation, Sichtdefinition
|
Programmierkomponenten
|
DB-Programmierung mit eingebetteten DB-Operationen
|
Benutzerkomponenten
|
Anwendungsprogramme, Anfrage und Update interaktiv
|
Transformationskomponenten
|
Optimierer, Auswertung, Plattenzugriffssteuerung
|
Data Dictionary (Datenwörterbuch)
|
Aufnahme der Daten aus Definitionskomponenten, Versorgung der anderen Komponenten
|
Schema-Architektur
—> Zusammenhang zwischen
- Konzeptuellen Schema (Ergebnis der Datendefinition)
- Internen Schema (Festlegung der Dateiorganisationen und Zugriffspfade)
- Externen Schema (Ergebnis der Sichtdefinition)
- Anwendungsprogrammen (Ergebnis der Anwendungsprogrammierung)

—> Ziele
- Trennung der semantischen Datensicht von der physischen Speicherung (Speicherstruktur) der Daten
- möglichst weitgehende Vermeidung von Abhängigkeiten zwischen Anwendungsprogramm und physischer Datenspeicherung (Datenunabhängigkeit der Anwendungsprogramme)
- physische Speicherung kann geändert werden, ohne Programmänderung!
—> Trennung Schema — Instanz
- Schema (Metadaten, Datenbeschreibungen)
- Instanz (Anwenderdaten, Datenbankzustand oder -ausprägung)
—> Datenbankschema besteht aus
- internem, konzeptuellen, externen Schema und den Anwendungsprogrammen
—> im konzeptuellen Schema etwa
- Strukturbeschreibungen
- Integritätsbedingungen
- Autorisierungsregeln (pro Benutzer für erlaubte DB-Zugriffe)
Datenunabhängigkeit
- Stabilität der Benutzerschnittstelle gegen Änderungen
- physisch: Änderungen der Dateiorganisationen und Zugriffspfade haben keinen Einfluss auf das konzeptuelle Schema
- logisch: Änderungen am konzeptuellen und gewissen externen Schemata haben keine Auswirkungen auf andere externe Schemata und Anwendungsprogramme
- mögliche Auswirkungen von Änderungen am konzeptuellen Schema:
- eventuell externe Schemata betroffen (Ändern von Attributen)
- eventuell Anwendungsprogramme betroffen (Rekompilieren der Anwendungsprogramme, eventuell Änderungen nötig) - nötige Änderungen werden jedoch vom DBMS erkennt und überwacht

Datenmodellierung

Transaktionen
- Einheit der Verarbeitung im Mehrbenutzerbetrieb
- Commit = erfolgreicher Abschluss
- Abort = Abbruch - zu synchronisierende Einheit im Mehrbenutzerbetrieb
- Einheit für Datenwiederherstellung (keine partiellen Effekte)
Eigenschaften aktueller DBMS
- Drei-Ebenen-Architektur nach ANSI-SPARC
- einheitliche Datenbanksprache (SQL = Structured Query Language)
- Einbettung dieser Sprache in kommerzielle Programmiersprache
- diverse Werkzeuge für die Definition, Anfrage und Darstellung von Daten und den Entwurf von Datenbanken-Anwendungsprogrammen und der Benutzer-Interaktion
- kontrollierter Mehrbenutzerbetrieb, Zugriffskontrolle und Datensicherheitsmechanismen
—> einige konkrete Systeme sind beispielsweise MySQL, Microsoft SQL Server 2005 oder Tamino
—> Einsatzgebiete unterscheiden sich von den klassischen wie zum Beispiel Buchhaltungssystemen bis hin zu den aktuellen Anwendungen wie entscheidungsunterstützende Systeme oder Data Mining
—> Datenbankgrößen
Yahoo! Data Warehouse
|
100 TB
|
WalMart Data Warehouse
|
0,5 PB
|
amazon.com
|
25 TB
|
US Library of Congress
|
10-20 TB
|
Google Index
|
?? —> 8 Mrd. Dokumente < ??
|
Entwicklungslinien
70er und 80er Jahre:
- Relationale Datenbanksysteme
- Daten in Tabellenstrukturen
- 3-Ebenen-Konzept
- Deklarative DML
- Trennung DML / Programmiersprache
80er und 90er Jahre:
- Wissensbanksysteme
- Daten in Tabellenstrukturen
- Stark deklarative DML integrierte Datenbankprogrammiersprache - Objektorienterte Datenbanksysteme
- Daten in komplexeren Obejktstrukturen (Trennung Objekt und seine Daten)
- Deklaration oder navigierende DML
- oft integrierte Datenbankenprogrammiersprache
- oft keine vollständige Ebenentrennung
heute:
- Unterstützung für spezielle Anwendungen
- Multimediadatenbanken: Verwaltung multimedialer Objekte
- XML-Datenbanken: Verwaltung semistruktuierter Daten
- Verteilte Datenbanken: Verteilung von Daten auf verschiedene Rechnerkonten
- Föderierte Datenbanken, Multidatenbanken, Mediatoren: Integration von Daten aus
heterogenen Quellen
- Mobile Datenbanken: Datenverwaltung auf Kleinstgeräten
Relationale Datenbanken - Daten als Tabellen
- der DB Markt wird heute völlig dominiert von DB-Sytsemen, die das relationale Datenmodell unterstützen
- führende Hersteller von diesen sind beispielsweise Oracle, Microsoft (Access, SQL Server), IBM, Software AG oder MySQL (Freeware)
- relational = beeinflusst vom mathematischen Konzept der Relation (Kreuzprodukt)
- Relationale Datenbanken sind im wesentlichen Sammlungen von Relationen
- Relationen kann man sich als Tabellen vorstellen, die aus Datensätzen bestehen, die alle dieselbe (homogene) Feldstruktur aufweisen
- Fett geschriebene Zeilen: Relationsschema
- weitere Einträge in der Tabelle: Relation
- eine Zeile der Tabelle: Tupel (Datensatz)
- eine Spaltenüberschrift: Attribut
- ein Eintrag: Attributwert
—> Spezifikation der Tabellen = Schema der relationalen Datenbank
Integritätsbedingungen: Schlüssel
- Attribute einer Spalte identifizieren eindeutig gespeicherte Tupel: Schlüsseleigenschaft (=Primary Key)
- Attributionskombinationen können auch Schlüssel sein
- Schlüssel können durch Unterstreichen gekennzeichnet werden

Integritätsbedingungen: Fremdschlüssel
- Schlüssel einer Tabelle können in einer anderen (oder derselben) Tabelle als eindeutige Verweise genutzt werden: Fremdschlüssel, referenzielle Integrität
- etwa MNr als Verweise auf Musiker
- ein Fremdschlüssel ist ein Schlüssel in einer „fremden“ Tabelle

—> Neben Primär- und Fremdschlüsseln können in SQL angegeben werden:
- mit der default-Klausel Defaultwerte für Attribute
- mit der create domain Anweisung benutzerdefinierte Weiterreiche
- mit der check-Klausel weitere lokale Integritätsbedingungen innerhalb der zu definierenden Wertebereiche, Attribute und Relationenschema

Datendefinition in SQL (= Structured Quere Language)
- SQL ist die populärste und am meist verbreitete relationale Datenbanksprache
- jede relationale DBMS „versteht“ SQL
—> Mögliche Wertebereiche
INT / INTEGER / INTEGER4
|
Für ganze Zahlen (ohne Nachkommastelle) bis ca. 2000000000
|
DECIMAL / NUMERIC
|
Für Zahlen mit Nachkommastelle
|
SMALLINT
|
Kleinere ganze Zahlen
|
FLOAT
|
Gleitkommazahl, evtl in exponential- (wissenschaftlicher) Schreibweise
|
CHARACTER / CHAR
|
Zeichenketten mit fester Länge
|
CHARACTER VARYING / VARCHAR
|
Für Zeichenketten variabler Länge
|
TEXT
|
Für Text mit bis zu 65.535 Zeichen
|
DATE
|
Für Daten im Format JJJJ-MM-TT
|
TIME
|
Für Zeitangaben im Format HH:MM:SS
|
DATETIME
|
Für Datums- und Zeitangaben im Format JJJJ-MM-TT und HH:MM:SS
|
Nullwerte
- not null schließt in bestimmten Spalten Nullwerte als Attributwerte aus
- Kennzeichnung von Nullwerte in SQL durch null; hier ⊥
- null repräsentiert die Bedeutung „Wert unbekannt“, „Wert nicht anwendbar“ oder „Wert existiert nicht“, gehört aber zu keinem Wertebreich
- null kann in allen Spalten auftauchen, außer in Schlüsselattributen und den mit "not null" gekennzeichneten
Anfrageoperationen auf Tabellen
- Basisioperationen auf Tabellen, die die Berechnung von neuen Ergebnistabellen aus gespeicherten Datenbanktabellen erlauben
- Operationen werden zur sogenannten Relationenalgebra zusammengefasst
- Mathematik: Algebra ist definiert durch Wertebereich sowie darauf definierten Operationen
—> für Datenbankanfragen entsprechen die Inhalte der Datenbank den Werten, Operationen sind dagegen Funktionen zum Berechnen der Anfrageergebnisse - Anfrageoperationen sind beliebig kombinierbar und bilden eine Algebra zum "Rechnen mit Tabellen“ - die sogenannte relationale Algebra oder auch Relationenalgebra
Relationenalgebra

Selektion
—> Auswahl von Zeilen einer Tabelle anhand eines Selektionsprädikats
Projektion
—> Auswahl von Spalten durch Angabe einer Attributliste
—> entfernt doppelte Tupel
Natürlicher Verbund
—> verknüpft Tabellen über gleichbenannte Spalten, indem er jeweils zwei Tupel verschmilzt, falls sie dort gleich Werte aufweisen
—> Tupel, die keinen Partner finden, werden eliminiert
Umbenennung
—> Anpassung von Attributnamen mittels Umbenennung durch ein „…as…“
Mengenoperationen
—> Vereinigung r1 ∪ r2 von zwei Relationen r1 und r2: sammelt die Tupelmengen zweier Relationen unter einem gemeinsamen Schema auf
—> Attributmengen beider Relationen müssen identisch sein
—> Attributmengen beider Relationen müssen identisch sein
—> Differenz r1 - r2 eliminiert die Tutel aus der ersten Relation, die auch in der zweiten Relation vorkommen
—> Durchschnitt r1 ∩ r2: ergibt die Tutel, die in beiden Relationen gemeinsam vorkommen
Sprachen für Datenbanken: SQL (= Structured Quere Language)
SQL Software
- XXAMPP: Paket zur einfachen Installation diverser Software inkl. MySQL, Apache Webserver, etc
Nutzung von XAMPP
- XAMOO Control Panel starten
- Apache und MySQL starten
- im Browser „localhost“ eingeben
- auf „phpMyAdmin“ klicken
- dann öffnete sich die Seite um Datenbanken zu erstellen
- auf SQL klicken und mit den Befehlen die Datenbank erstellen
In diesem Video sehen Sie kurz, wie das eben Beschriebene, erfolgt.
SQL Grundbegriffe
—> SQL hat seine eigene Terminologie für die relationalen Grundbegriffe
—> wichtig sind die englischen Formen dieser Grundbegriffe, weil SQL mit englischen
Schlüsselworten arbeitet
Schlüsselworten arbeitet
DEUTSCH
|
ENGLISCH
|
Tabelle
|
table
|
Spalte
|
column
|
Zelle
|
row
|
Wertebreiche
|
domain
|
—> wie fast jede DB-Sprache setzt sich auch SQL aus zwei Teilsprachen zusammen
- einer Definitionssprache (englisch „data definition language“ DDL)
—> enthält Befehlsformate, mit denen man Datenbankschmata definieren und manipulieren kann (Schemaevolution) - einer Datenmanipulationssprache (englisch „data manipulation language“ DML)
—> bietet Befehle zum Formulieren von Anfragen und Änderungen von Datenbankzuständen - das Gerüst jedes SQL-Befehls besteht aus englischen Schlüsselworten wie
- Select
- From
- Where
—> Schlüsselworte sind reserviert und dürfen nicht an anderen Stellen als beispielsweise Tabellennamen genutzt werden
Erzeugen von Tabellen = Erzeugen der Datenschemata
- Erzeugung der Datenbank
- create database Name
- use Name - Erzeugung von Tabellen
- create table Tabellenname
- Wertebereiche für einzelne Spalten eingeben
—> der foreign key kennzeichnet Spalten als Fremdschlüssel
Create Table Beispiel:

Datenbanken in Datenbank laden = insert
Syntax:

—> optionale Attributliste ermöglicht das Einfügen von unvollständigen Tupeln

SQL Anfragen
SELECT
|
- Projektionsleiste
- arithmetische Operationen und Aggregatfunktionen |
FROM
|
- zu verwendende Relationen, evtl. Umbenennungen
|
WHERE
|
- Selektions-, Verbundbedingungen
- geschachtelte Anfragen |
GROUP BY
|
- Gruppierung for Aggregatfunktionen
|
HAVING
|
- Selektionsbedingungen an Gruppen
|
Select
Auswahl von Tabellen, die from-Klausel
—> einfachste Form: hinter jedem Relationennamen kann optional eine Tupelvariante stehen
Beispiel:

Kartesisches Produkt (Kreuzprodukt)
—> bei mehr als einer Relation wird das kartesische Produkt gebildet
Beispiel:

—> alle Kombinationen werden ausgegeben
Natürlich Verbund in SQL92
—> frühe SQL-Versionen
- üblicherweise realisierter Standard in aktuellen Systemen
- kennen nur Kreuzprodukt, keinen expliziten Verbundoperator
- Verbund durch Prädikat hinter „where“ realisieren
- üblicherweise realisierter Standard in aktuellen Systemen
- kennen nur Kreuzprodukt, keinen expliziten Verbundoperator
- Verbund durch Prädikat hinter „where“ realisieren
Beispiel:

Tupelvariablen und Relationennamen
Anfrage:

ist äquivalent zu

Präfixe für Eindeutigkeit
—> Attribut MNr existiert sowohl in der Tabelle Ablum als auch in Musiker
—> richtig mit Präfix
—> richtig mit Präfix

Tupelvariablen für mehrfachen Zugriff
—> Einführung von Tupelvariablen erlaubt mehrfachen Zugriff auf eine Relation

—> Spalten lauten dann

Tupelvariablen für Eindeutigkeit
—> bei der Verwendung von Tupelvariablen, kann der Name einer Tupelvariablen, kann der Name einer Tupelvariablen zur Qualifizierung eines Attributs benutzt werden

Die where-Klausel
—> Formen der Bedingung:
- Vergleich eines Attributs mit einer Konstanten:
Attribut ⩉ Konstante
- Vergleich zwischen zwei Attributen mit kompatiblen Wertebereichen:
Attribut1 ⩉ Attribut2
- logische Konrektoren or, and und not
- Vergleich eines Attributs mit einer Konstanten:
Attribut ⩉ Konstante
- Vergleich zwischen zwei Attributen mit kompatiblen Wertebereichen:
Attribut1 ⩉ Attribut2
- logische Konrektoren or, and und not

Verbundbedinung
—> Verbundbedingung hat die Form
"relation1.attribut = relation2.attribut"
Beispiel:

Schachtelung von Anfragen
—> für Vergleiche mit Wertemengen notwendig:
- Standardvergleiche in Verbindung mit den Quantoren all (⩝) oder any (∋)
- spezielle Prädikate für den Zugriff auf Mengen, in und exists
- Standardvergleiche in Verbindung mit den Quantoren all (⩝) oder any (∋)
- spezielle Prädikate für den Zugriff auf Mengen, in und exists
in-Prädikat und geschachtelte Anfragen
—> Notation: "attribut in ( SFW-block )
Beispiel:

—> not in kann für Bildung von Differenzen verwendet werden, z.B. für die Anfrage „Musiker ohne Album“

Select weitere
—> Bereichsselektion: "attrib between konstante1 and konstante2"
—> ist die Abkürzung für:
"attrib ≥ konstante1 and
attrib ≤ konstante2"
Beispiel:

Skalare Ausdürcke
—> skalare Operationen auf
- numerischen Werftenbereichen: etwas +,-,*,/
- Strings: Operationen wie char_length (aktuelle Länge eines Springs), die Konkatenationen || und die Operationen substring (Suchen einer Teilzeichenkette an bestimmten Positionen des Strings)
- Datumstypen und Zeitintervallen: Operationen wie current_date (aktuelles Datum), current_time (aktuelle Zeit), +,- und *
- numerischen Werftenbereichen: etwas +,-,*,/
- Strings: Operationen wie char_length (aktuelle Länge eines Springs), die Konkatenationen || und die Operationen substring (Suchen einer Teilzeichenkette an bestimmten Positionen des Strings)
- Datumstypen und Zeitintervallen: Operationen wie current_date (aktuelles Datum), current_time (aktuelle Zeit), +,- und *
Sortierung mit order by
—> Notation: "order by attributliste"
Beispiel:

—> Sortierung aufsteigend (asc) oder absteigend (desc)
—> Sortierung als letze Operation einer Anfrage —> Sortierattribut muss in der select-Klausel vorkommen
—> Sortierung als letze Operation einer Anfrage —> Sortierattribut muss in der select-Klausel vorkommen
Behandlung von Nullwerten
—> skalare Ausdrücke: Ergebnis null, sobald Nullwert in die Berechnung eingeht
—> in allen Aggregatfunktionen bis auf count (*) werden Nullwerte vor Anwendung der Funktion entfernt
—> fast alle Vergleiche mit Nullwert ergeben Wahrheitswert unknown statt (false oder true)
—> Ausnahme: is null ergibt true, is not null ergibt false
—> in allen Aggregatfunktionen bis auf count (*) werden Nullwerte vor Anwendung der Funktion entfernt
—> fast alle Vergleiche mit Nullwert ergeben Wahrheitswert unknown statt (false oder true)
—> Ausnahme: is null ergibt true, is not null ergibt false
—> Boolesche Ausdrücke basieren dann auf dreiwertiger Logik
Sichten = virtuelle Relationen (bzw virtuelle Datenbankobjekte in anderen Datenmodellen) - englisch: view
—> Sichten sind externe DB-Schemata folgend der 3-Ebenden-Schemaarchitektur
—> Sichtdefinition
- Relationenschema (implizit oder explizit)
- Berechnungsvorschrift für virtuelle Relationen, etwa SQL-Anfrage
- Relationenschema (implizit oder explizit)
- Berechnungsvorschrift für virtuelle Relationen, etwa SQL-Anfrage
—> Vorteile
- Vereinfachung von Anfragen für den Benutzer der Datenbank, etwa indem oft benötigte Teilanfragen als Sicht realisiert werden
- Möglichkeiten der Strukturierung der Datenbankbeschreibung, zugeschnitten auf Benutzerklassen
- logische Datenunabhängigkeit ermöglicht Stabilität der Schnittstelle für Anwendungen gegenüber Änderungen der Datenbankstruktur (entsprechend in umgekehrter Richtung)
- Beschränkung von Zugriffen auf eine Datenbank im Zusammenhang mit der Zugriffskontrolle
- Möglichkeiten der Strukturierung der Datenbankbeschreibung, zugeschnitten auf Benutzerklassen
- logische Datenunabhängigkeit ermöglicht Stabilität der Schnittstelle für Anwendungen gegenüber Änderungen der Datenbankstruktur (entsprechend in umgekehrter Richtung)
- Beschränkung von Zugriffen auf eine Datenbank im Zusammenhang mit der Zugriffskontrolle
—> Probleme
- automatische Anfragetransformation
- Durchführung von Änderungen auf Sichten
- automatische Anfragetransformation
- Durchführung von Änderungen auf Sichten
Definition von Sichten

Beispiel:

Kriterien für Änderungen auf Sichten
—> Effektkonformität
Benutzer sieht Effekt als wäre die Änderung auf der Sichtrelation direkt ausgeführt worden
Benutzer sieht Effekt als wäre die Änderung auf der Sichtrelation direkt ausgeführt worden
—> Minimalität
Basisdatenbanken sollte nur minimal geändert werden, um den erwähnten Effekt zu erhalten
Basisdatenbanken sollte nur minimal geändert werden, um den erwähnten Effekt zu erhalten
—> Konsistenzerhaltung
Änderung einer Sicht darf zu keinen Integritätsverletzungen der Basisdatenbank führen
Änderung einer Sicht darf zu keinen Integritätsverletzungen der Basisdatenbank führen
—> Respektierung des Datenschutzes
Wird die Sicht aus Datenschutzgründen eingeführt, darf der bewusst ausgeblendete Teil der Basisdatenbank von Änderungen der Sicht nicht betroffen werden
Projektionssicht

Datenbank Entwurf
Wie spezifiziere ich bei einer bestimmen Anwendung die „richtigen“ Tabellen?

Schritt 1: Modellbildung der realen Welt: Beispiel

Datenbankentwurf Schritt 1: Das Entity-Relationship-Modell
Entity: Objekt der realen Welt, oder Objekt aus der Vorstellungswelt, auch Datenobjekt oder
Informationsobjekt
—> Beispiele: Produkte, Personen, Musiker, Bestellungen, Vorlesungen
Informationsobjekt
—> Beispiele: Produkte, Personen, Musiker, Bestellungen, Vorlesungen
Relationship: Beziehung zwischen Entities
—> Beispiele: Musiker produziert Album, Dozent hält Vorlesung, Kunde bestellt
Produkt
—> Beispiele: Musiker produziert Album, Dozent hält Vorlesung, Kunde bestellt
Produkt
Attribut: EIgenschaften von Entities und Beziehungen
—> Beispiele: Namen des Studenten, Titel der Vorlesung
—> Beispiele: Namen des Studenten, Titel der Vorlesung
Beziehungstypen
1:1 Beziehung
—> jedem Element vom Entity-Typ 1ist maximal ein Element von Entity-Typ 2 zugeordnet und umgekehrt
bspw. eine Frau ist verheiratet mit einem Mann
—> jedem Element vom Entity-Typ 1ist maximal ein Element von Entity-Typ 2 zugeordnet und umgekehrt
bspw. eine Frau ist verheiratet mit einem Mann

1:N Beziehung
—> jedem Element von Entity-Typ 1 sind beliebig viele Elemente von Entity-Typ 2 zugeordnet und zu jedem Element von Entity-Typ 2 gibt es maximal ein Element von Entity-Typ 1
bspw. Mutter hat Kinder
—> jedem Element von Entity-Typ 1 sind beliebig viele Elemente von Entity-Typ 2 zugeordnet und zu jedem Element von Entity-Typ 2 gibt es maximal ein Element von Entity-Typ 1
bspw. Mutter hat Kinder

N:1 Beziehung
—> invers (umgekehrt) zu 1:N
—> auch funktionale Beziehung
—> zweistellige Beziehungen, die eine Funktion beschreiben:
- jedem Entity eines Entity-Typs E1 wird maximal ein Entity eines Entity-Typs E2 zugeordnet
—> invers (umgekehrt) zu 1:N
—> auch funktionale Beziehung
—> zweistellige Beziehungen, die eine Funktion beschreiben:
- jedem Entity eines Entity-Typs E1 wird maximal ein Entity eines Entity-Typs E2 zugeordnet

N:M Beziehung
—> jedem Element vom Entity-Typ 1 sind beliebig viele Elemente von Entity-Typ 2 zugeordnet und umgekehrt = keine Einschränkung
bspw. Bestellung beinhaltet Produkte
—> jedem Element vom Entity-Typ 1 sind beliebig viele Elemente von Entity-Typ 2 zugeordnet und umgekehrt = keine Einschränkung
bspw. Bestellung beinhaltet Produkte

Kardinalitäten: Beispiel:

Schritt 2: Umsetzen des konzeptionellen Schemas in das Datenbankschema
—> Abbildung des E-R-Modells in relationales Modell
—> Umsetzung in Tabellenspezifikation
—> Umsetzung in Tabellenspezifikation
Abbildung der
- Entities und Beziehungen auf Relationschema = Tabellen
- Attribute auf Attribute des Relationenschemas = Spaltennamen
- Schlüssel bei Entity-Typen werden übernommen
- Schlüssel bei Beziehungen werden wie folgt festgelegt:
- 1:1-Beziehung: einer der beiden Schlüssel wird Primärschlüssel
- 1:N-Beziehung: Schlüssel der N-Seite wird Primärschlüssel
- N:M-Beziehung: beide Schlüssel werden zusammen Primärschlüssel
Datenbankenentfwurf: Entwurfsaufgabe
- Datenhaltung für mehrere Anwendungssysteme und mehrere Jahre
- daher: besondere Bedeutung
- Anforderungen an Entwurf:
- Anwendungsdaten jeder Anwendung sollen aus Daten der Datenbank ableitbar sein (und zwar möglichst effizient)
- nur „vernünftige“ (wirklich benötigte) Daten sollen gespeichert werden
- nicht-redundante Speicherung

Anforderungsanalyse
- Vorgehensweise: Sammlung des Informationsbedarf in den Fachabteilungen
- Ergebnis:
- informale Beschreibung (Texte, tabellarische Aufstellungen, Formblätter, usw.) des Fachproblems
- Trennen der Information über Daten (Datenanalyse) von den Informationen über Funktionen - "Klassischer" DB-Entwurf:
- nur Datenanalyse und Folgeschritte - Funktionsentwurf:
- siehe Methoden des Software Engineering
Konzeptioneller Entwurf
- erste formale Beschreibung des Fachproblems
- Sprachmittel: semantisches Datenmodell
- Vorgehensweise:
- Modellierung von Sichten z.B. für verschiedene Fachabteilungen
- Analyse der vorliegenden Sichten in Bezug auf Konflikte
- Integration der Sichten in ein Gesamtschema - Ergebnis: konzeptionelles Gesamtschema, z.B. (E)ER-Diagramm
Datenbankmodell

ein Datenbankmodell legt fest:
- statische Eigenschaften
- Objekte
- Beziehungen
inklusive der Standard-Datentypen, die Daten über die Beziehungen und Objekte darstellen können - dynamische Eigenschaften wie
- Operationen
- Beziehungen zwischen Operationen - Integritätsbedinungen an
- Objekte
- Operationen
- klassische Datenbankmodele sind speziell geeignet für
- große Infomationsmengen mit relativ starrer Struktur
- die Darstellung statischer Eigenschaften und Integritätsbedingungen - Entwurfsmodelle: (E)ER- Modell, UML
- Realisierungsmodelle: Relationenmodell, objektorientierte Modelle
Datenbankentwurf: ER-Beispiel

Datenbankentwurf: ER-Modell - Werte
- Werte: primitive Datenelemente, die direkt darstellbar sind
- Wertemengen sind beschrieben durch Datentypen, die neben einer Wertemenge auch die Grundoperationen auf diesen Werten charakterisieren
- ER-Modell: vorgegebene Standard-Datentypen, etwa die ganzen Zahlen int, die Zeichenketten string, Datumswerte date etc
- jeder Datentyp stellt Wertebereich mit Operationen und Prädikaten dar
Datenbankentwurf: ER-Modell - Entities
- Entities sind die in einer Datenbank zu repräsentierenden Informationseinheiten
- im Gegensatz zu Werten nicht direkt darstellbar, sondern nur über ihre Eigenschaften beobachtbar
- Entities sind eingeteilt in Entity-Typen, etwa E1,E2
- Menge der aktuellen Entities: 𝛔(E1)= {e1,e2,…..en}
Datenbankentwurf: ER-Modell - Attribute
- Attribute modellieren Eigenschaften von Entities oder auch Beziehungen
- alle Entities eines Entity-Typs haben dieselben Arten von Eigenschaften; Attribute werden somit für Entity-Typen deklariert
- textuelle Notation E(A1: D1,….Am:Dm)
Datenbankentwurf: ER-Modell - Schlüssel
Identifizierung durch Schlüssel
- Schlüsselattribute: Teilmenge der gesamten Attribute eines Entity-Typs E(A1….Am)
{S1…..Sk} ⊆ {A1…..Am} - in jedem Datenbankzustand identifizieren die aktuellen Werte der Schlüsselattribute eindeutig Instanzen des Entity-Typs E
- bei mehreren möglichen Schlüsselkandidaten: Auswahl eines Primärschlüssels
- Notation: markieren durch Unterstreichung:
E(….,S1,….,Si,….)
Datenbankentwurf: ER-Modell - Beziehungstypen
- Beziehungen zwischen Entities werden zu Beziehungstypen zusammengefasst
- allgemein: beliebige Anzahl n ≥ 2 von Entity-Typen kann an einem Beziehungstyp teilhaben
- zu jedem n-stelligen Beziehungstyp R gehören n Entity-Typen E1…En
- Ausprägung eines Beziehungstyps
𝛔(R) ⊆ 𝛔(E1) x 𝛔(E2) x … x 𝛔(En) - Notation
- textuelle Notation: R(E1,E2,…,En)
- wenn Entity-Typ mehrfach an einem Beziehungstyp beteiligt:
Vergabe von Rollennamen möglich
Datenbankentwurf: ER-Modell - Beziehungsattribute
- Beziehungen können ebenfalls Attribute besitzen
- Attributdeklaratinen werden beim Beziehungstyp vorgenommen
- gilt auch hier für alle Ausprägungen eines Beziehungstyps —> Beziehungsattribute
- textuelle Notation: R(E1,…..En;A1,…..Ak)
Datenbankentwurf: ER-Modell - Merkmale von Beziehungen
- Stetigkeit oder Grad:
- Anzahl der beteiligten Entity-Typen
- häufig: binär
- Beispiel: Lieferant liefert Produkt - Kardinalität oder Funktionalität:
- Anzahl der eingehenden Instanzen eines Entity-Typs
- Formen 1:1, 1:n, m:n
- stellt Integritätsbedinungen dar
- Beispiel: maximal 5 Produkte pro Bestellung

Beispiele:

Datenbankentwurf: ER-Modell - [min,max]-Notation

- schränkt die möglichen Teilnahmen von Instanzen der beteiligten Entity-Typen an der Beziehung ein, indem ein minimaler und ein maximaler Wert vorgegeben wird
- Notation für Kardinaltitätsangaben an einem Beziehungstyp
R(E1,….,Ei[mini,maxi],…,En) - Kardinalitätsbedinung: mini ≤ | {r | r ∈ R ⋀ r.Ei = ei} | ≤ maxi
- spezielle Wertangabe für maxi ist *
Datenbankentwurf: ER-Modell - Kardinalitätsangaben
- [0,*] legt keine Einschränkung fest (default)
- R (E1[0,1],E2) entspricht einer (partiellen) funktionalen Beziehung zugeordnet ist
- totale funktionale Beziehung wird durch R(E1,[1,1],E2) modelliert
Beispiele:
- partielle funktionale Beziehung
lagert_in (Produkt [0,1], Fach [0,3])
—> „Jedes Produkt ist im Lager in einem Fach abgelegt, allerdings wird ausverkauften bzw. gegenwärtig nicht lieferbaren Produkten kein Fach zugeordnet. Pro Fach können maximal drei Produkte gelagert werden.“ - totale funktionale Beziehung
liefert (Lieferant [0,*], Produkt [1,1])
—> „Jedes Produkt wird durch genau einen Lieferant geliefert, aber ein Lieferant kann durchaus mehrere Produkte liefern.“
Datenbankentwurf: ER-Modell - Abhängige Entity-Typen
- abhängiger Entity-Typ: Identifikation über funktionale Beziehungen
- abhängige Entities im ER-Modell: Funktionale Beziehung als Schlüssel

Datenbankentwurf: ER-Modell - Abhängige Entity-Typen 2
- mögliche Ausprägung für abhängige Entities

Datenbankentwurf: ER-Modell - IST-Beziehung
- Spezialisierung-/Generalisierungsbeziehung oder auch IST-Beziehung (englisch is-a relationship)
- textuelle Notation: E1 IST E2
- IST-Beziehung entspricht semantisch einer injektiven, funktionalen Beziehung

Datenbankentwurf: ER-Modell - IST-Beziehung Eigenschaften
- Jeder Album-Instanz ist genau eine Produkt-Instanz zugeordnet —> Album-Instanzen werden durch die funktionale IST-Beziehung identifiziert
- nicht jedes Produkt ist zugleich ein Album (z.B. Single, Film,..)
- Attribute des Entity-Typs Produkt treffen auch auf Alben zu: „vererbte“ Attribute
- nicht nur die Attributdeklarationen vererben sich, Soden auch jeweils die aktuellen Werte für eine Instanz
Datenbankentwurf: ER-Modell - IST-Beziehung: Alternative Notation

Datenbankentwurf: ER-Modell - IST-Beziehung: Kardinalitätsangaben
- für Beziehung E1 IST E2 gilt immer: IST (E1[1,1],E2[0,1])
- jede Instanz von E1 nimmt genau einmal an der IST-Beziehung teil, während Instanzen des Obertyps E2 nicht teilnehmen müssen
- Aspekte wie Attributvererbung werden hiervon nicht erfasst
Datenbankentwurf: ER-Modell - Optionalität von Attributen

Datenbankentwurf: ER-Modell - Weitere Konzepte
- Strukturierte Attributwerte im ER-Modell

Datenbankentwurf: Vorgehen
- ER-Modellierung von verschiedenen Sicht auf Gesamtinformation, z.B. für verschiedene Fachabteilungen eines Unternehmens —> konzeptueller Entwurf
- Analyse und Integration der Sichten
- Ergebnis: konzeptionelles Gesamtschema - Verteilungsentwurf bei verteilter Speicherung
- Abbildung auf konkretes Implementierungsmodell (z.B. Relationenmodell) —> logischer Entwurf
- Datendefinition, Implementierung und Wartung —> physischer Entwurf
Datenbankentwurf: ER-Abbildung
- Entity-Typen und Beziehungstypen: jeweils auf Relationenschemata
- Attribute: Attribute des Relationenschemas, Schlüssel werden übernommen
- Kardinalitäten der Beziehungen: durch Wahl der Schlüssel bei den zugehörigen Relationschemata ausdrücken
- in einigen Fällen: Verschmelzen der Relationenschemata von Entity- und Beziehungstypen
- zwischen den verbleibenden Relationschemata diverse Fremdschlüsselbedingungen einführen
Abbildungen von Beziehungstypen
- neues Relationenschema mit allen Attributen des Beziehungstyps, zusätzlich Übernahme aller Primärschlüssel der beteiligten Entity-Typen
- Festlegung der Schlüssel:
- m:n-Beziehung: beide Primärschlüssel zusammen werden Schlüssel im neuen Relationenschema
- 1:n-Beziehung: Primärschlüssel der n-Seite (bei der funktionalen Notation die Seite ohne Pfeilspitze) wird Schlüssel im neuen Relationenschema
- 1:1-Beziehung: beide Primärschlüssel werden je ein Schlüssel im neuen Relationenschema, der Primärschlüssel wird dann aus diesen Schlüsseln gewählt
Mögliche Verschmelzungen
- optionale Beziehungen ([o,1] oder [0,n]) werden nicht verschmolzen
- bei Kardinalitäten [1,1] oder [1,n] (zwingende Beziehungen) Verschmelzung möglich:
- 1:n-Beziehung: das Entity-Relationschema der n-Seite kann in das Relationenschema der Beziehung integriert werden
- 1:1-Beziehung: beide Entity-Relationenschemata können in das Relationenschema der Beziehung integriert werden
Verschmelzung bei 1:n-Beziehung

- da Album von einem Musiker/Band eingespielt werden muss (zwingende Beziehung), können Relationenschemata Album und EingespieltVon verschmolzen werden

Verschmelzung bei 1:1-Beziehung


IST-Beziehung


Mehrstellige Beziehungen

- jeder beteiligte Entity-Typ wird nach den obigen Regeln behandelt
- für Beziehung Bestellt werden Primärschlüssel der drei beteiligen Entity-Typen in das resultierende Relationenschema aufgenommen
- Beziehungen ist allgemeiner Art (k:m:n-Beziehung): alle Primärschlüssel bilden zusammen den Schlüssel
Übersicht über die Transformationen

Datenbankenentwurf: Normalformen
Funktionale Abhängigkeiten
- funktionale Abhängigkeit zwischen Attributmengen X und Y einer Relation
Wenn in jedem Tupel der Relation der Attributwert unter den X-Komponenten den Attributwert unter den Y-Komponenten festlegt.
- unterscheiden sich zwei Tutel in den X-Attributen nicht, so haben sie auch gleiche Werte für alle Y-Attribute
- Notation für funktionale Abhängigkeit (FD, von functional dependency): X —> Y
- Beispiel:
AlbumNr —> Titel, MNr, Name
MNr —> Land
Schlüssel als Spezialfall
- für Beispiel:
AlbumNr —> Titel, Jahr, Genre, MNr, Name, Land - Immer: AlbumNr —> AlbumNr, dann gesamtes Schema auf rechter Seite
- Wenn linke Seite minimal: Schlüssel
- Formal: Schlüssel X liegt vor, wenn für Relationenschema R FD X —> R gilt und X minimal
—> Ziel des Datenbankentwurfs: alle gegebenen funktionalen Abhängigkeiten in „Schlüsselabhängigkeiten“ umformen, ohne dabei semantische Informationen zu verlieren
Schemaeigenschaften
- Relationschemata, Schlüssel und Fremdschlüssel so wählen, dass
1. alle Anwendungsdaten aus den Basisrelationen hergeleitet werden können
2. nur semantisch sinnvolle und konsistente Anwendungsdaten dargestellt werden können
3. die Anwendungsdaten möglichst nicht-redundant dargestellt werden - hier: Forderung 3
- Redundanzen innerhalb einer Relation: Normalformen
- globale Redundanzen: Minimalität
Normalformen
- legen Eigenschaften von Relationenschemata fest
- verbieten bestimmte Kombinationen von funktionalen Abhängigkeiten in Relationen
- sollen Redundanzen und Anomalien vermeiden
Erste Normalform
- erlaubt nur atomare Attribute in den Relationenschemata, d.h. als Attributwerte sind Elemente von Standard-Datentypen wie „integer“ oder „string“ erlaubt, aber keine Konstruktiven wie „array“ oder „set“

Zweite Normalform
- partielle Abhängigkeit liegt vor, wenn ein Attribut funktional schon von einem Teil des Schlüssels abhängt

Eliminierung partieller Abhängigkeiten

Zur Erreichung der 2. Normalform: Zerlegung (Dekomposition) der Relationen
Kriterien damit das Ergebnis der Zerlegung korrekt ist:
- Verlustlosigkeit (=Verbundtreue):
im ursprünglichen Relationenschemata R enthaltene Informationen müssen im neuen (zerlegten) Relationenschemata R’ rekonstruierbar sein - Abhängigkeitserhaltung (=Abhängigkeitstreue)
im ursprünglichen Relationschemata R enthaltene funktionale Abhängigkeiten müssen auf das neue (zerlegte) Relationenschemata R’ übertragbar sein
Abhänigkeitstreue
|
Verbundtreue
|
|
|
Verbundtreue Dekomposition

Nicht verbundtreue Dekomposition

Dritte Normalform
- eliminiert (zusätzlich) transitive Abhängigkeiten
- etwa AlbumNr —> MNr und MNr —> Name
- man beachte: 3NF betrachtet nur Nicht-Schlüsselattribute als Endpunkt transitiver Abhängigkeiten
Eliminierung transitiver Abhängigkeiten

Boyce-Codd-Normalform
- Verschärfung der 3NF: Eliminierung transitiver Abhängigkeiten auch zwischen Primattributen
- BCNF kann jedoch die Abhängigkeitstreue verletzen, daher oft nur bis 3NF
Minimalität
- Global Redundanzen vermeiden
- andere Kriterien (wie Normalformen) mit möglichst wenig Schemata erreichen
Schemataeigenschafften zusammengefasst

ÜBUNGEN AUS DEN VORLESUNGEN
- Musiker-Übung
Vorgehen:
- Erstellen einer neuen Datenbank durch „create Database“
- Erstellen von der Tabelle „Musiker" und der Tabelle „Album“
Tabelle Musiker:
—>„MNr“ also Musiker Nummer ist der Primarykey
Tabelle Album:
—> „ANr“ also Album Nummer ist der Primarykey
—> „foreign key“ kennzeichnet Fremdschlüssel (Primärschlüssel von Musiker)
- „Füllen“ der Tabelle durch „insert into table“
Tabelle Musiker:
—> rechts werden die Spalten angezeigt, die die Reihenfolge der „Füllung“ bestimmen
—> der Primarykey wird nicht in Anführungszeichen geschrieben
Tabelle Album:
—> für „MNr“ wird der entsprechende Primärschlüssel aus der Tabelle Musiker genommen
- Führen Sie folgende Aktionen durch:
Projektion: Lassen Sie sich die Liste aller Musikernamen anzeigen.

Selektion: Lassen Sie sich alle Albendatensätze (=Zeilen) aus dem Jahr 2005 (in meinem Fall 2016) anzeigen.

Lassen Sie sich alle Musiker aus Deutschland (in meinem Fall England) auflisten.

Kombinieren Sie in einer Anfrage auf beide Tabellen eine Bedingung (where...) auf dem Preis mit einer Bedingung auf das Land, und lassen Sie sich Titel, Musikername, Jahr, Preis und Land anzeigen.

2. Restaurant Übung
- In einer Datenbank sollen die Restaurantvorlieben von Studierenden erfasst werden. Jedes Restaurant hat eine Rest.nummer (RNR, Primärschlüssel), einen Namen, einen Inhaber sowie PLZ, Ort und Straße. Zu den Studierenden werden Matrikelnummer (MNR, Primärschlüssel), Name, Vorname, Alter und der Studiengang verwaltet. Schreiben Sie die SQL-Anweisung zur Erzeugung der Tabellen für STUDENT und RESTAURANT auf! Überlegen Sie sich passende Datentypen
Vorgehen:
—> Datenbank erstellen
—> Tabellen erzeugen
- Erzeugen sie eine dritte Tabelle STUDIREST (keineUmlaute/Sonderzeichen), in der erfasst wird, welche Studierende (Matrikelnummer) welches Restaurant
(RNR) bevorzugen! Nehmen Sie hier SRNR (Studi-Rest-Nummer) als Primärschlüssel und geben sie gegebenenfalls den Fremdschlüssel an.
- Füllen Sie die Tabellen RESTAURANT und STUDENT per SQL Anweisung mit mindestens 7 Studenten und 5 Restaurants (müssen keine „realen“ Daten sein). Füllen Sie die Tabelle STUDI-REST mit den fünf Lieblingsrestaurants der sieben Studierenden, dabei soll
ein Restaurant das Lieblingsrestaurant von mindestens 3 Studierenden sein, und 2 Studierende sollten mindestens 2 Lieblingsrestaurants haben und
ein Restaurant soll von Niemanden bevorzugt werden.
- Führen Sie den Verbund der Tabellen STUDENT und STUDI-REST durch, und geben Sie das SQL Kommando (select ...) dazu an.

- Nennen wir die Ergebnistabelle von Aufgabe 4 STUDENT-REST. Führen Sie den Verbund der Tabellen STUDENT-REST und RESTAURANT durch und geben Sie das SQL Kommando dazu an.
 3. Zug Übung
3. Zug Übung
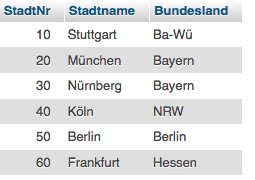
ENTITY-RELATIONSHIP-MODELLENTITIES - Bahnhof
- Stadt
- Zug
ATTRIBUTE - Bahnhof
- PLZ
- Straße
- Stadtname
- BHFNr - Stadt
- Stadtname
- Bundesland
- StadtNr - Zug
- Wagons
- ZugNr
RELATIONS - liegt in —> Bahnhof in Stadt
- Ziel —> Zug kommt am Bahnhof an
- Start —> Zug startet am Bahnhof
- verbindet —> Zug fährt Bahnhof an



—> Städte: mindestens 5 Einträge, Bahnhöfe: mindestens 6 Einträge, Züge: mindestens 6 Einträge
—> verbindet: mindestens 18 Einträge, entsprechend ergänzen mit Abfahrtszeit & Ankunftszeit, Abfahrts- und Ankunftsgleis.


1:N
—> Ein Bahnhof kann nur in einer Stadt liegen, aber eine Stadt kann mehrere Bahnhöfe haben
N:M
N:M
—> wenn auf beiden Seiten eine 1:N Beziehung vorliegt, dann ist es eine N:M Beziehung
—> in einem Bahnhof können mehrere Züge an- und abfahren und ein Zug kann in mehreren Bahnhöfen an- und abfahren




4. Für einen Bahnhof lassen Sie sich einen Fahrplan anzeigen. (z.B. Abfahtsfahrplan des Bahnhofs).

4. UEFA U21 EM - ER-Modell
Modellieren Sie ein ER Modell und setzen Sie es in eine Datenbank um:
für ein Verwaltungs- oder Infosystem für eine Sportveranstaltung am Beispiel einer UEFA Fussball U21 EM 2017.
für ein Verwaltungs- oder Infosystem für eine Sportveranstaltung am Beispiel einer UEFA Fussball U21 EM 2017.

Entity 1: Land
GRUPPE
|
NAME
|
LANDNr (LNr)
|
A
|
England
|
1
|
A
|
Slowakei
|
2
|
A
|
Schweden
|
3
|
A
|
Spanien
|
4
|
B
|
Polen
|
5
|
B
|
Portugal
|
6
|
B
|
Serbien
|
7
|
B
|
EJR Mazedonien
|
8
|
C
|
Italien
|
9
|
C
|
Deutschland
|
10
|
C
|
Dänemark
|
11
|
C
|
Tschechische Republik
|
12
|
Entity 2: Stadion
ORT
|
NAME
|
STADIONNr (SNr)
|
Kielce
|
Kielce Stadium
|
10
|
Lublin
|
Lublin Stadium
|
20
|
Bydgoszcz
|
Bydgoszcz Stadium
|
30
|
Gdynia
|
Gdynia Stadium
|
40
|
Tychy
|
Tychy Stadium
|
50
|
Krakow
|
Krakow Stadium
|
60
|
Entity 3: Spieltermin
SPIELTERMINNr (STNr)
|
DATUM
|
STADIONNr (SNr)
|
GRUPPENPHASE
|
1
|
16. Juni 2017
|
10
|
Gruppenphase 1
|
2
|
16. Juni 2017
|
20
|
Gruppenphase 1
|
3
|
17. Juni 2017
|
30
|
Gruppenphase 1
|
4
|
17. Juni 2017
|
40
|
Gruppenphase 1
|
5
|
18. Juni 2017
|
50
|
Gruppenphase 1
|
6
|
18. Juni 2017
|
60
|
Gruppenphase 1
|
7
|
19. Juni 2017
|
10
|
Gruppenphase 2
|
8
|
19. Juni 2017
|
20
|
Gruppenphase 2
|
9
|
20. Juni 2017
|
30
|
Gruppenphase 2
|
10
|
20. Juni 2017
|
40
|
Gruppenphase 2
|
11
|
21. Juni 2017
|
50
|
Gruppenphase 2
|
12
|
21. Juni 2017
|
60
|
Gruppenphase 2
|
13
|
22. Juni 2017
|
20
|
Gruppenphase 3
|
14
|
22. Juni 2017
|
10
|
Gruppenphase 3
|
15
|
23. Juni 2017
|
30
|
Gruppenphase 3
|
16
|
23. Juni 2017
|
40
|
Gruppenphase 3
|
17
|
24. Juni 2017
|
50
|
Gruppenphase 3
|
18
|
24. Juni 2017
|
60
|
Gruppenphase 3
|
19
|
27. Juni 2017
|
50
|
Halbfinale
|
20
|
27. Juni 2017
|
60
|
Halbfinale
|
21
|
30. Juni 2017
|
60
|
Finale
|
Entity 4: Ergebnis
ERGEBNISNr (ENr)
|
SPIELTERMINNr (STNr)
|
LANDNr (LNr)
|
TORE
|
30
|
1
|
3
|
0
|
35
|
1
|
1
|
0
|
40
|
2
|
4
|
1
|
45
|
2
|
2
|
2
|
50
|
3
|
6
|
2
|
55
|
3
|
7
|
0
|
60
|
4
|
5
|
5
|
65
|
4
|
8
|
0
|
70
|
5
|
10
|
2
|
75
|
5
|
12
|
0
|
80
|
6
|
11
|
0
|
85
|
6
|
9
|
2
|
90
|
7
|
2
|
1
|
95
|
7
|
1
|
2
|
100
|
8
|
4
|
2
|
105
|
8
|
3
|
2
|
110
|
9
|
7
|
2
|
115
|
9
|
8
|
2
|
120
|
10
|
6
|
1
|
125
|
10
|
5
|
3
|
130
|
11
|
12
|
3
|
135
|
11
|
9
|
1
|
140
|
12
|
10
|
3
|
145
|
12
|
11
|
0
|
150
|
13
|
2
|
3
|
155
|
13
|
3
|
0
|
160
|
14
|
1
|
3
|
165
|
14
|
4
|
0
|
170
|
15
|
7
|
0
|
175
|
15
|
5
|
1
|
180
|
16
|
8
|
2
|
185
|
16
|
6
|
4
|
190
|
17
|
12
|
2
|
195
|
17
|
11
|
4
|
200
|
18
|
9
|
1
|
205
|
18
|
10
|
0
|
210
|
19
|
1
|
2
|
215
|
19
|
10
|
2
|
220
|
20
|
5
|
3
|
225
|
20
|
9
|
1
|
230
|
21
|
10
|
1
|
235
|
21
|
5
|
0
|
- Welche Mannschaften haben am 18. Juni gespielt?

- Wie viele Mannschaften haben 3 Tore erzielt?

- Welche Mannschaften waren im Halbfinale und aus welchen Gruppen kamen diese?

- In welchen Stadien erfolgte die Gruppenphase 1?

- Welche Mannschaften haben zu welchem Spieltermin im Krakow Stadium gespielt?

FAZIT
Die Blockveranstaltungen von Herrn Noll zum Thema „Informationssysteme“ wurde meistens so gegliedert, dass uns zunächst theoretisches Basiswissen vermittelt wurde, mit dem wir dann Aufgaben bearbeiten sollten. Auf diese Weise konnten wir die neu erlernten Inhalte vertiefen und selber anwenden. Ich bin immer gerne zu dieser Veranstaltung gegangen, da Herr Noll diese so gestaltet hat, dass es einem Spaß macht, und er war jeder Zeit für Fragen und Hilfe offen.
Keine Kommentare:
Kommentar veröffentlichen